Data Engineering: The Invisible Backbone of Innovation
Data Engineering: The Invisible Backbone of Innovation
Have you ever wondered how a massive company like Amazon or Netflix processes millions of transactions a second without breaking? Or how an AI model like Gemini gets the “fuel” it needs to answer your questions?
The answer is Data Engineering.
While Data Scientists are often called the “sexiest job of the 21st century,” Data Engineers are the architects and plumbers who build the cities they live in. Without a solid data infrastructure, even the most advanced AI is just a car without an engine.
What Exactly is Data Engineering?
At its core, Data Engineering is the practice of designing, building, and maintaining the systems that allow data to flow from a source to a destination. Data Engineers take “raw” data—which is often messy, fragmented, and full of errors—and transform it into a high-quality stream that business departments can actually use.
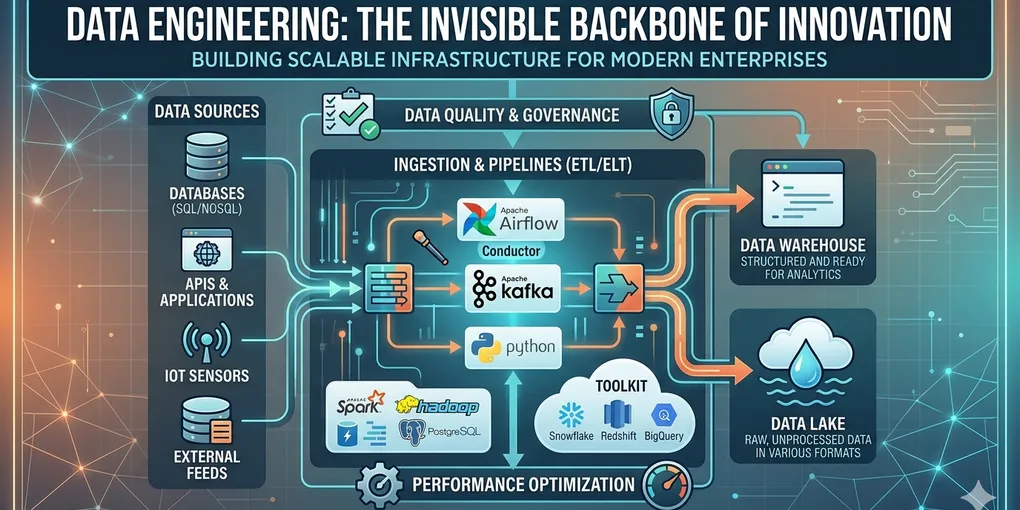
The 5 Pillars of the Data Lifecycle
To understand the day-to-day work of a data engineer, you have to look at these five components:
- Data Collection: Gathering raw info from APIs, sensors, and databases.
- Data Storage: Choosing between a Data Warehouse (structured) or a Data Lake (raw/unstructured).
- Data Processing: Cleaning and normalizing data so it’s “clean” enough to trust.
- Data Pipelines: The automated “highways” (ETL/ELT) that move data from Point A to Point B.
- Data Quality & Governance: Ensuring the data is secure, private, and accurate.
Why Can’t We Just Use Raw Data?
Raw data is like crude oil—you can’t put it in your car and expect it to run. It needs to be refined. Data engineering provides:
- Scalability: Systems that handle 1,000 or 1,000,000 rows with the same efficiency.
- Compliance: Ensuring we follow laws like GDPR or HIPAA.
- Reliability: Making sure the dashboard doesn’t break when a source format changes.
Data Engineering vs. Data Science: What’s the Difference?
Many people confuse these two, but they are distinct roles that work together in a relay race.
| Aspect | Data Engineering | Data Science |
|---|---|---|
| Focus | Infrastructure & Pipelines | Analysis & Modeling |
| Objective | Prepare and manage data | Extract insights and predictions |
| Tools | Spark, Kafka, SQL, Airflow | Python, R, Jupyter, TensorFlow |
| Output | Clean, structured datasets | Predictive models & reports |
The Toolkit: How We Build the Future
As I’ve been sharing in my recent project updates, a modern Data Engineer needs a versatile belt of tools:
- Storage: PostgreSQL, MongoDB, Snowflake.
- Processing: Apache Spark, Hadoop.
- Orchestration: Apache Airflow (The “Conductor” of the pipeline).
- Cloud: AWS (Redshift), Google Cloud (BigQuery).
Final Thoughts
Data Engineering is no longer a “back-office” task—it is a strategic requirement. Whether I’m building a logistics brokerage platform like Pangana Fleet or a data tool like my KPI Generator, the goal is always the same: Turn noise into knowledge.